大学时对计算理论知之甚少,计算理论、编译原理都是为了应试而学,所用的课本也纯粹是乏味的理论,让人很难提起兴趣。而国外一些权威课本,可能知识总结不算精粹,讲解过程也掺杂着各种比喻,甚至是“过多”的讲述背景故事,但若是真的对这门学科感兴趣,这样的课本也许才是更好的选择。学习这样的课本,不仅仅能让人理解理论知识,更能了解这些理论知识的由来和意义。
好了,废话不多说。读完第一部分-程序和机器,稍作概述:
确定性有限自动机
确定性有限自动机有若干状态,其中包括开始状态和接受状态(结束状态)。通过接收某个字符,使自动机的状态进行转换。接收指定的字符可以使自动机达到最终的接受状态,其他字符则可能永远无法达到接受状态。
确定性有限自动机在读入字符的时候,最终所处的状态一定是完全确定的,它不存在冲突也没有遗漏。
非确定性有限自动机
非确定性有限自动机去除了确定性有限自动机的确定性约束。
非确定性有限自动机可以同一时刻处于多个状态,它在进行某个字符读取时,可能处于状态2,也可能处于状态3。对这些可能的状态都应该进行记录。当非确定有限自动机同一时刻的状态中,存在一个接受状态时,该机器就认为接受读取到的字符串。
确定性下推自动机
下推自动机是在有限自动机的基础上进行了功能扩展。下推自动机主要是对存储部分进行了扩展,增加了一个栈对读取的字符进行弹入弹出操作。
确定性下推自动机的约束是“不能存在冲突”:不能在任何状态上,由于冲突的规则而使机器的状态在下一次移动中有二意性。
确定性下推自动机可以做括号匹配,能识别例如"(())()()(()())“这样的字符串,进行这样的字符串识别的时候,可以认为读取”(“时进行入栈操作,读取”)“时进行出栈。但是这样的计算仍然很有局限性,因为他的栈其实只是一个计数器,并且它的规则只区分“栈为空”或“栈不为空”。因此想用用确定性下推自动机做回文识别是很困难的。
非确定性下推自动机
为突破确定性下推自动机的局限,使下推自动机能识别回文,我们可以去掉下推自动机的确定性约束。没有确定性约束的下推自动机,顾名思义就叫做非确定性下推自动机。
一台非确定性下推自动机会记录同时存在的多种状态,每个状态也有自己的存储栈。当非确定性下推自动机识别字符串时,其中某条状态转换为接受状态,就认为该字符串是可识别的。
非确定性下推自动机和确定性下推自动机是不等价的,非确定性下推自动机不能转化成确定性下推自动机,因为非确定下推自动机的每种可能状态都有自身的栈信息,确定性下推自动机无法把所有可能的栈组合成一个栈。
图灵机
将一条无限长的纸带穿过黑盒子,黑盒子可以左右移动纸带并修改在黑盒子中那部分纸带上的内容(擦除原有内容,再写入新的内容),黑盒子内部可以存储某些状态。图灵机的运作步骤如下:
1. 黑盒子对纸带上的内容进行读取,读取的内容可能会改变黑盒子的内部状态
2. 黑盒子根据最新的内部状态,对纸带进行写入和移动
3. 当完成移动后,纸带原先的部分必定移出黑盒子,另外一部分会进入黑盒子,回到步骤1,黑盒子对新进入的纸带重复以上操作。
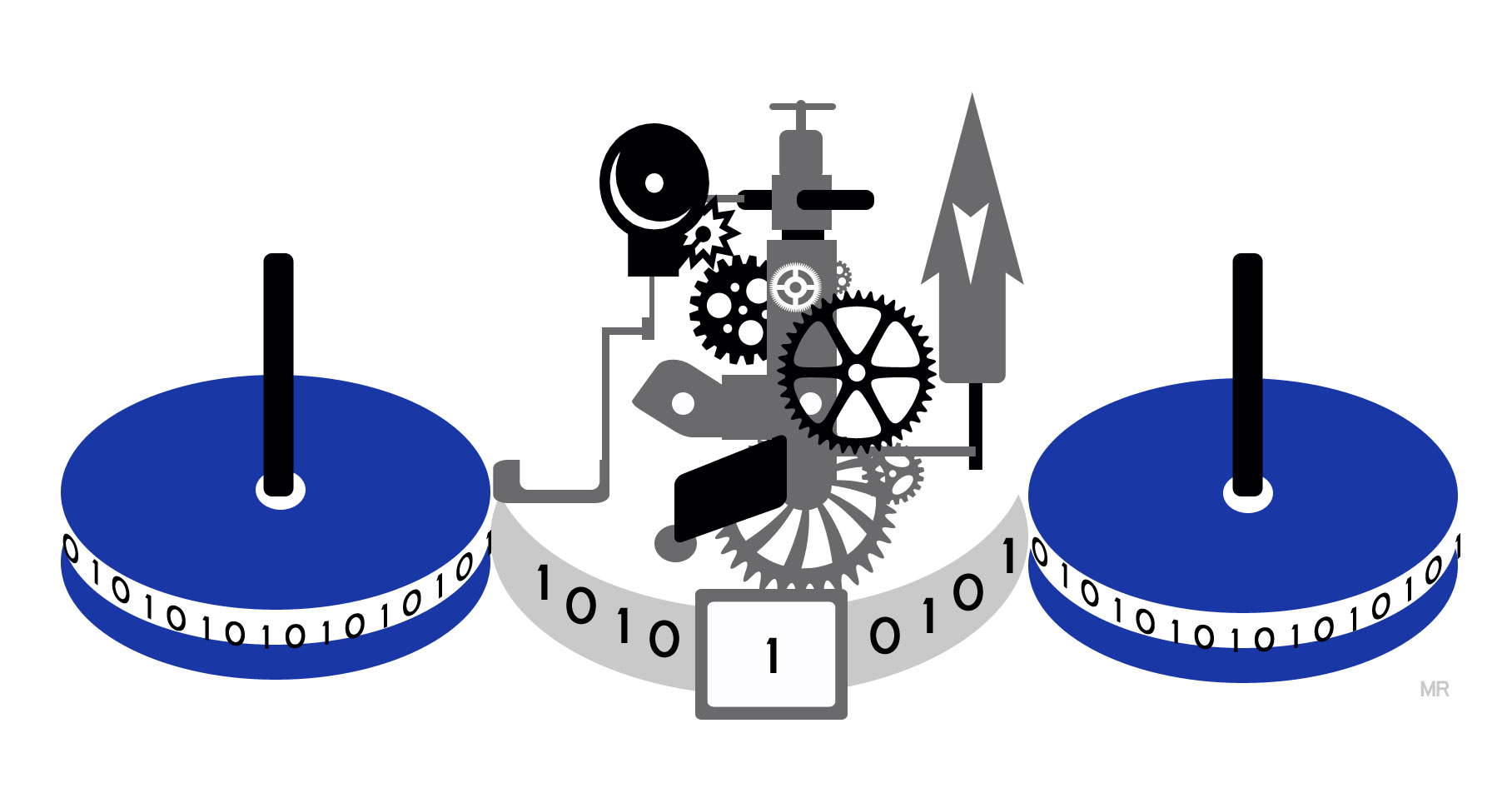
图灵机是目前为止最全能的计算机器,只需要通过以上简单的原理,可以实现任何现代计算机的计算功能。图灵机在添加一些附加功能(比如存储、子例程、多条纸带)后,可以提升一定的便捷性,但是不不能提升自身的计算能力。
存在一种通用图灵机(UTM,Universal Turing Machine),它可以在自身的纸带上模拟出任何一种图灵机,包括通用图灵机。通俗的说就是可以在图灵机上面模拟出一台虚拟的图灵机,这台虚拟的图灵机上还可以模拟出图灵机。
不得不感叹这些先贤们惊人的创造力!乍一看我们日常使用的计算机和这些理论相去甚远。很难想象我们使用的复杂计算机就是在这些基础理论上一点一滴的建立起来的。
作为一名 WEB 开发人员,可能研究这些理论并没有多大的作用。现代高级编程技术让我们不需要任何底层理论就能写出出色的程序,但是求知欲不会停止,想去探索就应该去探索。有句话说得好——如果你想从头开始制作苹果派,必须先创造整个宇宙。
认真去做一件事时,是需要某种信念的。